
ASR&SD挑战赛正式打响 基线系统和开发训练集发布
发布时间 : 2021-08-09 阅读量 : 3381

在数字经济快速发展的时代,数据成为生产要素,算力成为重要生产力,推动各大行业数字化转型和生产力变革。以数据、算法和算力“三驾马车”驱动的人工智能,正在改变基础学科和各个行业的创新模式。鼓励AI开发者积极创新,引领时代发展,是应对未来社会变革的必然要求。
由北京Magic Data、中科院声学所和江苏师范大学主办,MagicHub.io开源社区、上海白玉兰开源开放研究院、华为MindSpore社区、英特尔OpenVINO中文社区协办的“对话式AI语音识别及说话人识别(ASR&SD)挑战赛”自开展以来已经收到四十多个来自各大高校和企业参赛队伍注册报名。报名通道于8月6日关闭,主办方正式开启下一阶段的赛程,8与7日正式向参赛队伍开放开发训练集和基线系统。
开发训练集
主办方针对赛道一“对话场景下的语音识别(ASR)准确率”和赛道二“对话场景下的说话人识别(Speaker Diarization)准确率”开放了以下训练数据集: 1.160小时中文对话数据,主办方通过邮件形式将下载链接发送到参赛者邮箱,下载时间为8月7日~8月9日24时止,请参赛者及时查收和下载。 2.MagicData开源的755小时ASR中文朗读数据,请参赛者登录MagicHub.io开源社区并注册社区账号进行数据集下载,下载地址为:https://magichub.io/cn/datasets/mandarin-chinese-scripted-speech-corpus-daily-use-sentence-command-and-query-sms/ 3.此外,赛道二SD赛道允许使用两个开源数据集:[VoxCeleb Data (openslr-49)],下载链接:http://www.openslr.org/49/和[CN-Celeb Corpus (openslr-82)] ,下载链接:http://www.openslr.org/82/供参赛者使用。
基线系统介绍
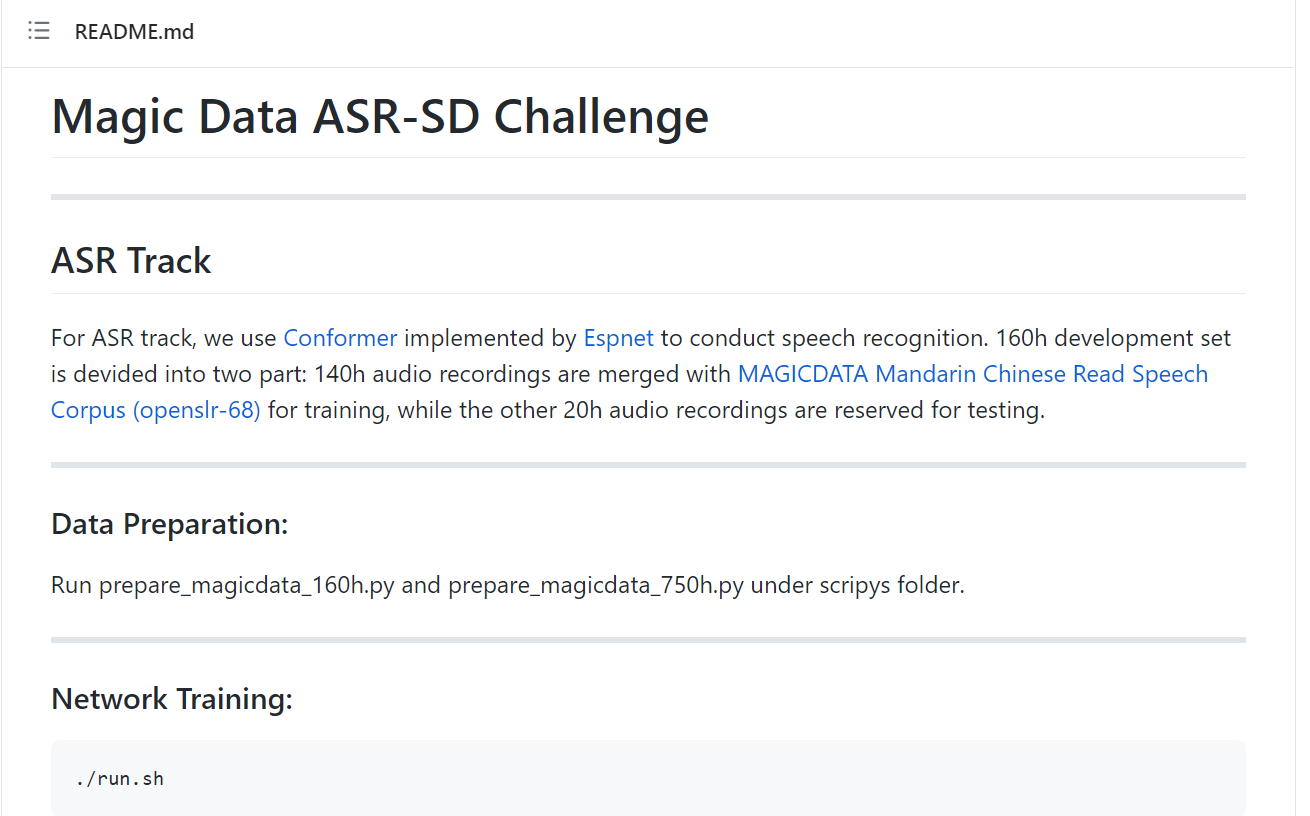
GitHub上基线系统教程
为了帮助参赛者快速、高质量完成模型开发和训练,主办方提供了基线系统,提供给参赛者使用。 我们基于 kaldi 与 espnet 等开源工具与项目搭建了简易的基线系统,赛道一ASR 赛道的基线系统我们使用了端到端系统,用 Conformer 对北京Magic Data提供的160小时中文对话数据和开源的755小时ASR中文朗读数据进行了训练。 赛道二SD赛道上,我们使用了 VBHMM-XVector 系统,训练时加入了 VoxCeleb 与 CN-Celeb 数据集,从而实现说话人特征的提取。详细的使用教程请见 :https://github.com/MagicHub-io/Magic-Data-ASR-SD-Challenge
基线系统答疑指导
参赛者在比赛过程中,对基线系统有任何问题,可在以下链接中提交:https://github.com/MagicHub-io/Magic-Data-ASR-SD-Challenge/issues,将有专家团队给予解答。
竞赛主委会支持团队
参赛者在挑战赛中遇到相关问题,可通过发送邮件至ncmmsc16th@163.com邮箱,邮件标题为“ASR&SD挑战赛疑问”,由组委会的以下资深技术专家提供专业技术问答和指导:
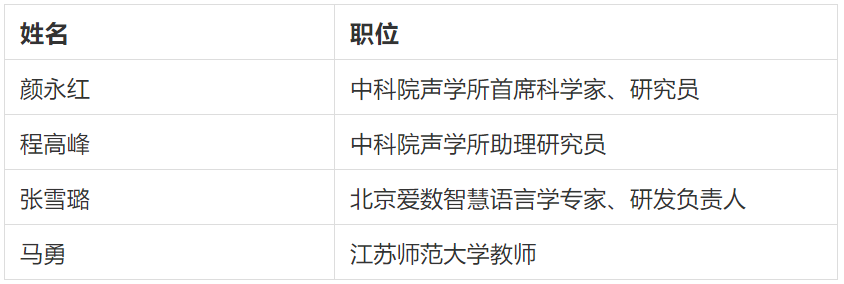
竞赛主委会支持团队
指导专家们均是在语音界积累丰富的研究和实战经验,在他们的指导下,相信会给参赛者带来不少启发。