
Magic Data方言对话数据集 让AI听懂你的乡音
发布时间 : 2020-11-27 阅读量 : 11248

有这么一个笑话,四川老太太在异地乘车,因人多被挤得直喊“孩子丢了”,大家纷纷帮她找孩子,最后她指着旁边的鞋子,大家恍然大悟,她找的是被挤丢的“鞋子”。
关于方言,中国俗话说“十里不同音,百里不同俗”,方言给跨地域沟通带来诸多不便,人与人沟通尚且如此,更何况基于语音识别的人工智能设备呢?
提升方言识别率 有利于优化AI产品体验
随着智能音箱、智能客服为代表的智能语音市场的不断扩大,方言成为语音交互体验的一大障碍。受方言影响,很多人讲普通话也夹带方言特色。比如广州人用粤语问智能音箱“我要不要返工”(注:“返工”在粤语中指的是“上班”),音箱可能给出“如果感觉不够好,你可以再做一次”之类答非所问的对话。
智能语音设备要想进一步扩大市场,满足不同地域用户使用需求,AI模型需要大量的方言数据集。对于智能客服来说,AI掌握多种方言,能够帮助客服提升服务质量,实现机器人“无感化”体验;也能帮助智能家居设备提高方言识别能力,更加精准识别主人命令,从而完成相应的操作。
自然对话数据集让AI学习原汁原味的方言
对于这一需求,Magic Data针对多方言自然对话场景和朗读场景,采集和标注多种方言对话数据集和口语朗读式数据集。数据集产品覆盖七大方言,帮助AI模型有效提升语音识别准确性。
为最大限度提升AI模型对方言的识别准确率,Magic Data采集的对话数据来自自然、真实的对话场景,表达风格口语化,对话自然流畅。
大量方言口语朗读式数据集 满足模型训练需求
Magic Data拥有超过一万小时的方言数据集储备量,除了方言自然对话数据集外,Magic Data还有方言口语式朗读数据集,方言数据集覆盖北方官话、吴语、湘语、赣语、闽语、粤语、客家话等七大方言,包括四川话、广东话、上海话、武汉话、长沙话、闽南话、郑州话、东北话等具体方言。
匹配发音词典助力模型高效训练
Magic Data的各个方言数据集,和一般语料库相比,除了音频和文本信息外,还包含了以下几个方面:
字词表:语言模型的核心点是基于方言语音的文本用字一致性,但因普通话和方言语音系统差异巨大,导致方言书写用字方面存在困难,Magic Data通过字词表为方言设定标准的用字体系,规范统一写法。
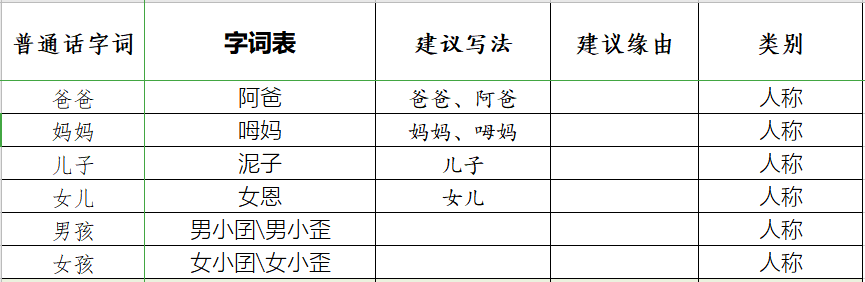
常用字词映射表(以上海话为例)
发音词典:为降低有限词汇(out ofvocabulary)对识别率的影响,Magic Data研发了自主知识产权的发音词典标注系统。发音词典词条和Magic DataASR数据集相匹配,并且覆盖字词在真实场景下的发音,包含了每个字单独发音,以及上下文中的真实发音包括变调信息等。方言发音词典包含超过10万条通用式词条,从而加快OOV问题的解决。

发音词典样例(以上海话为例)
平行语料:字词表和词典外,Magic Data方言口语朗读式数据集还提供平行语料,即方言文本对应的普通话文本。例如:上海话“吾明朝真呃有事体哎”,其对应的普通话文本为“我明天真的有事呢”等。
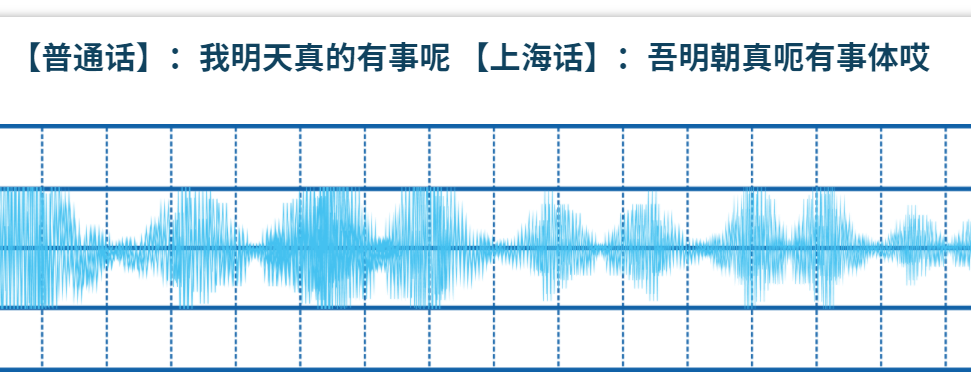
Magic Data官网样例含平行语料截图(以上海话为例)
数据集是破解语音识别中方言问题的关键。市场正在逐步重视方言识别,各大厂商也开始涉足这一领域。Magic Data提供丰富的方言数据集,帮助提升AI模型方言识别层面的准确度,扩大人工智能产品的市场投放范围,推动人工智能产品的发展和普及。
更多数据集欢迎咨询客服:400-900-5251,或者在官网进行了解。