
AICon 2021 | 从数据原材料和生产工具看AI产业发展源动力
发布时间 : 2021-12-01 阅读量 : 2263
2021 年是对话式 AI爆发元年,想要推动对话式人工智能的落地,除了依靠人机交互技术外,更需要百倍千倍以上规模的训练数据量。
01对话式AI是人机交互中的典型形态
无论是在所谓的虚拟世界中,还是在最近很火的“元宇宙”里,其中都提到很多关于对话式交流现象,人和人的交互,人和机器,人和虚拟世界的交互,“对话式”成了非常典型的一种交互形态。
相较于相对死板的朗读数据,对话数据里存在很多自然语言现象,包括一些迟疑,停顿,语句前后颠倒等等,这些情况机器在书面语中是没有办法学到的。举一个最常见的例子,比如你想让家里的智能音响放一首歌,在交互过程中很多人会产生说话迟疑,可能会说“嗯...我想听一首歌”,这个“嗯...”的声音发出来就会给识别带来极大错误率,所以用于机器学习的数据应反应真实场景,这才是实现无障碍人机对话的重要基础。
为了能直观展示对话式AI给模型带来的帮助,我们做了以下实验:
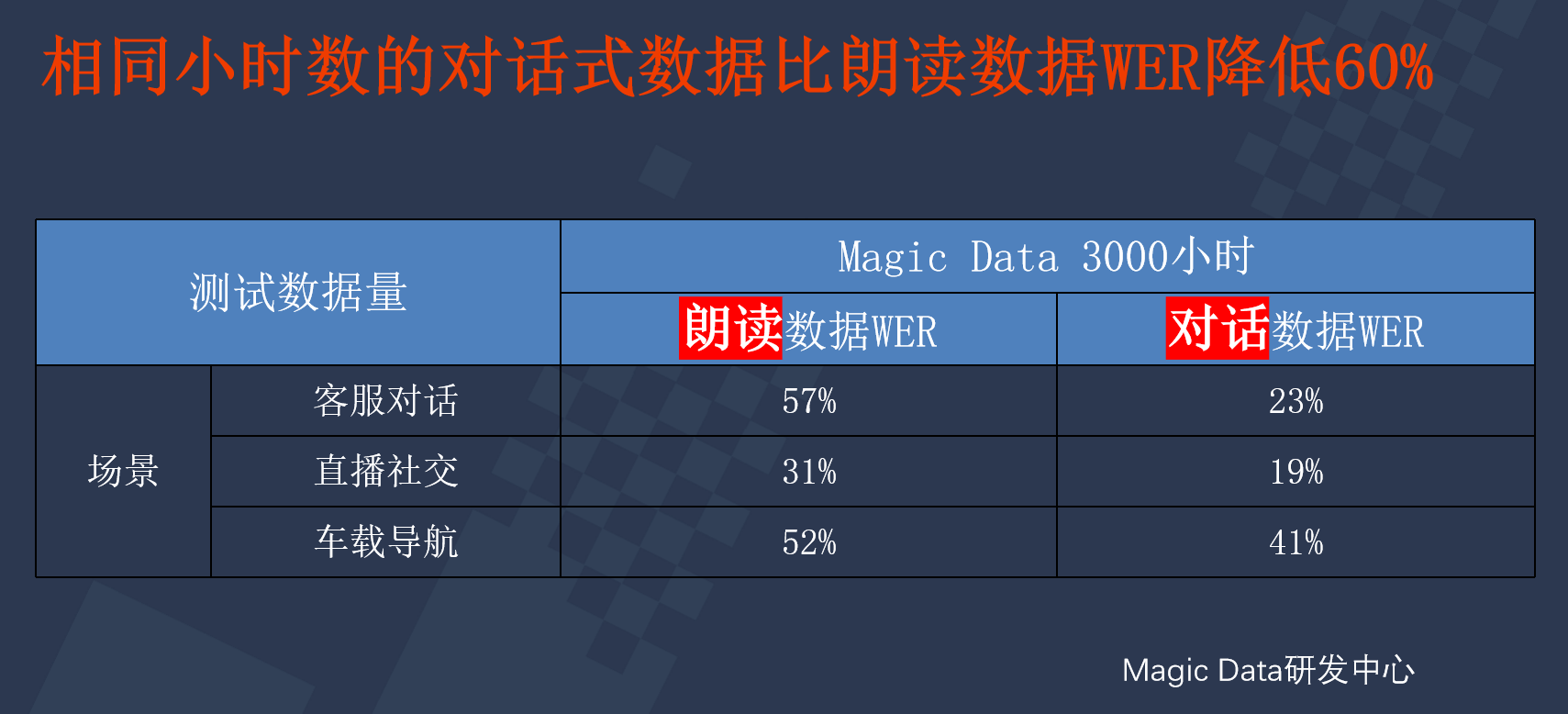
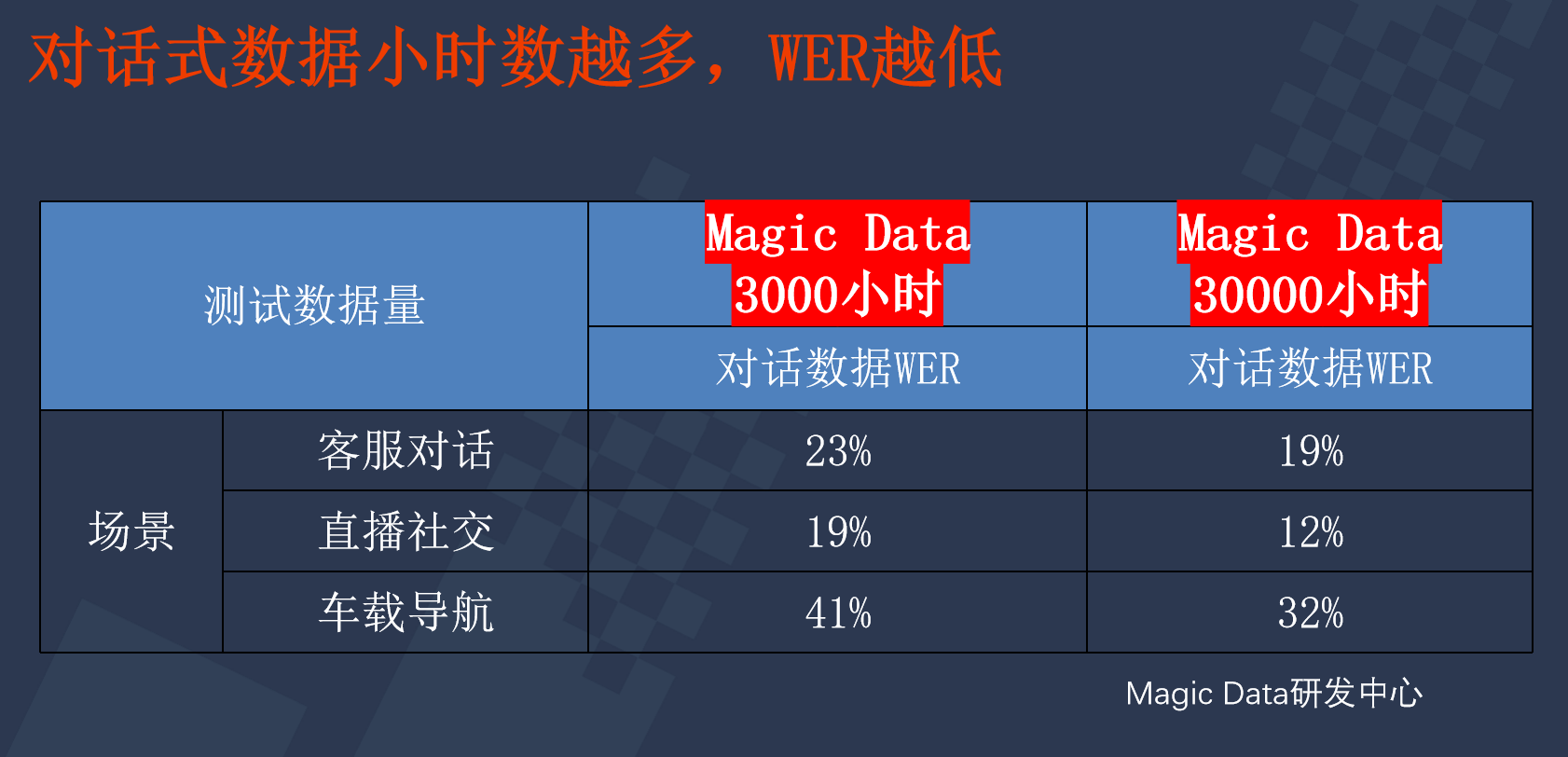
在三个场景下,分别使用相同小时数的朗读数据和对话数据,很明显使用对话数据的文字识别错误率更低。同时,对话数据量越多,识别效果越好。
 Magic Data研发中心实验数据
Magic Data研发中心实验数据
从以上实验数据可以看出,使用对话数据对于在真实场景下的识别效果都是更突出的。
除此之外,对话数据还有一个很重要的优势,它对于模型本身的鲁棒性,泛化性会带来更好的帮助,因为人在说话的时候会有发音变异、吞音现象等等,模型学习到这些数据对于真实场景下的识别也会有更好的帮助。
02数据原材料和生产工具
人工智能的基础是数据,对话式AI数据让人类能够自由地表达。
当前行业内,大部分人工智能数据都以朗读式为主,这使得让机器能像人一样理解自然语言成为了非常大的难题。Magic Data 拥有超过20万小时的数据产品,其中对话式数据产品有16万小时,涵盖超过60种语言,既有英语、日语等常用语,也提供马来语、阿拉伯语、印尼语、泰语等特色小语种,这些数据产品覆盖包括不限于智慧出行、智慧金融、智能社交、智能家居、智能终端等场景。针对于场景的多样化,Magic Data 不仅提供对话式语音数据产品,同时也提供图像、文本、音视频等多模态数据系统与服务。
数据生产“效率神器”帮助AI工作者快速完成数据标签化。
AI工作者在专注于模型的优化和迭代中,数据标签化是件非常重要的事情,可以说是占据整个机器学习生态链里超过一半的工作量。同时标签化的过程也存在诸多痛点:
一是多模态的融合。过去音频、文本、音视频大多是各自孤立,近两年间达到高度融合,短视频则是一个非常典型的场景。当这些多模态数据标签化需要同步完成时,就会涉及非常高的标签维度,对标注过程要求极其苛刻,如果由一个人完成这些步骤,几乎是不可行的事情。
二是标注员技能和任务不匹配。起初,数据标注任务由不具备专业知识的人也能完成,随着人工智能向前发展,未来可能变成各个行业的专家们才有机会来进行标签化工作。专家们如何在整个标签体系里更高效完成,是亟待解决的问题。
三是数据流转是否清晰。在数据流转过程中,是否可以通过清晰化、可视化的展现来跟进任务,是标签化工作能否快速完成的重要指标。
四是标注效率低。目前绝大多数数据标注还是依靠人工完成,效率极低,产出数据的数据原料不足直接导致跟不上机器学习的发展。
针对以上难点,Magic Data 于今年发布Annotator®智能化标注平台,除了能为企业提供训练数据“原材料”的基础支撑外,同时也提供数据标签化的高效生产工具,它能很好地解决以上问题——多模态标注、任务可拆分、可视化管理、智能化辅助。
目前Annotator®智能化标注平台正服务于全球机器学习领域的专家,多维度标签体系支持全球企业对AI数据的标签化需求,智能化预标和预审功能,能够帮助所有企业AI开发者降本增效。
据中国艾瑞报道,2022年全中国会有500万人从事数据标注行业,所有标注人员则更加需要高效的标注工具,这才能为AI研发人员提供更好的原材料来驱动AI模型训练。
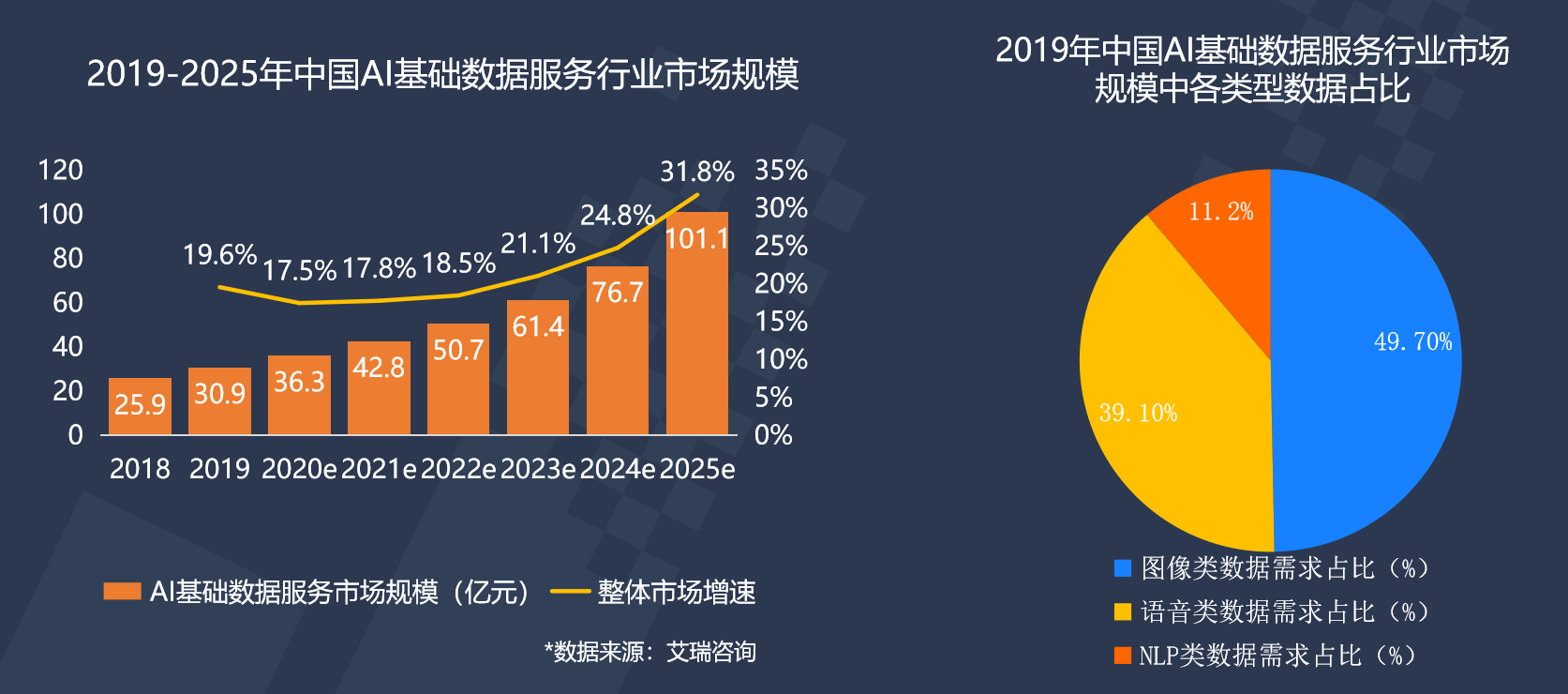 AI基础数据市场规模(艾瑞咨询)
AI基础数据市场规模(艾瑞咨询)
Magic Data 将与所有AI工作者一起,用高质量数据帮助企业AI产业落地。